Introduction
In this blog, we will discuss how we built a distributed task scheduler in Go. We will go through the architecture of a Task Scheduler and finally implementing it in Go
So What Exactly is a Task Scheduler
Let us understand this through a real world example, Imagine you run a resturant kitchen.Orders Comes in(tasks)-Some are urgrent(high priority) some can wait (low priority), You have multiple chefs(workers) who can cook in parallel,There’s a head chef(coordinator) who looks at the orders and assigns them to whichever chef is free.If a dish gets burned the head of the chef tells the cook to try again(retries).Some orders are scheduled for later e.g make this cake for 3PM.If a chef doesnt respond for 30 seconds(hypothetically xD), head chef assumes the chef has left and stops sending them orders.
Before understanding Task Scheduling we first need to understand what is a “Cron” (or “Cron Job”).Cron is a common unix utility designed to periodically launch arbitrary jobs at user defined times or intervals. i.e a Time-Based Scheduler. Cron is implemented using a single component called crond. This is a kind of daemon which wakes up every minute and checks if any task matches the current time and runs it on specific machine.
So, it seems simple and feasible… but as soon as you need to run tasks across many servers, or if you need high availability when that single crond instance dies, the limitations become clear.
For instance, if that one machine running crond crashes, the scheduled job doesn’t run at all. Furthermore, if the job takes 2 hours to finish but is scheduled to run every hour, you end up with overlapping processes that can lead to resource exhaustion and potentially crash the server.This is why we need a system that can manage tasks across a cluster of machines, ensuring that tasks are still executed even if a node fails, and intelligently preventing the kind of overlapping execution that can cripple a single server.
Distributed Task Scheduling is the process of managing and executing tasks across a cluster of multiple computers rather than a single machine. It solves the limitation of simple CronJob by decoupling the “When”(scheudling) from the “Where”(exectution)
Distributed Task Scheduling is essentially Cron on Steroids, it is the gear-5 of the CronJob designed for scale and reliability.
Architecture of our Distributed Task Scheduler(Conductor)
Let us first look at where our System fits
The Control Plane vs Data Plane Paradigm
Before diving into each component,lets understand a fundamental concept in distributed systems: Control Plane vs Data Plane.
Think like an airport:
Control Plane = Air Traffic Control - Makes decisions about where planes should go, when they should take off, manages the overall orchestration.
Data Plane = The Actual Aircraft - Does the real work of flying passengers from A to B.
In our task scheudler , Scheduler and Coordinator falls under the Control Plane where they decides what run wher it runs and who executes it and Worker comes under Data Plane where they actually execute the tasks
These Separation is Crucial because
-
Independent Scaling - Need more execution capacity? Add More Workers Controle plane stays the same
-
Fault Tolerance - A worker Crash doesnt bring down the scheduler
-
Single source of truth - The coordinator maintains consistent state about task assignment
The Scheduler - API Gateway
Scheduler is the public-facing HTTP Server that clients interact with,It’s Essesntially an API Gateway for our task system.
It Accepts Task Submissions via REST API, Validates incoming request, Forward Tasks to the Coordinator via gRPC,Provide task status queries and statistics
// The Scheduler connects to the Coordinator via gRPC
type Server struct {
db *db.DB
coordinatorClient grpcapi.CoordinatorServiceClient // gRPC client
coordinatorConn *grpc.ClientConn
stopCleanup chan struct{}
}
// When a task comes in via HTTP, it's forwarded to Coordinator via gRPC
func (s *Server) ScheduleTaskWithOptions(data string, opts db.TaskOptions) (string, error) {
if s.coordinatorClient != nil {
// Forward to coordinator via gRPC
resp, err := s.coordinatorClient.SubmitTask(ctx, &grpcapi.ClientTaskRequest{
Data: data,
Priority: int32(opts.Priority),
MaxRetries: int32(opts.MaxRetries),
TimeoutSeconds: int32(opts.TimeoutSeconds),
ScheduledAt: scheduledAt,
})
return resp.TaskId, nil
}
// Fallback: write directly to database
return s.db.CreateTaskWithOptions(data, opts)
}goThe Scheduler also runs a background cleaner loop that resets “zombie tasks”- tasks that got picked but never processed (maybe the coordinator crashed mid assignment)
func (s *Server) cleanupLoop() {
ticker := time.NewTicker(1 * time.Minute)
for {
// Reset tasks stuck in picked state for > 5 minutes
s.db.ResetStaleTasks(5 * time.Minute)
}
}goThe Coordinator - Brain
The Coordinator is the central orchestrator “the head chef”
from our resturant analogy.Its the most critical component of the systems
The Coordinator has many responsibilites such as Maintaining the registry of all active workers, Monitoring the worker health via heartbeats Picking tasks from the Database queue,Dispatch tasks to available workers, handling tasks status updates and retry logic
Why a Separate Conductor? Cant the scheduler dispatch tasks directly to workers? Yes, we can do it but separating them provides - 1. Centralized Worker Management - One component tracks all the workers 2. Consistent Task Distribution - Prevents double dispatching 3. Protocol Separation Prevents - HTTP for clients and gRPC for internal communication
The Coordinator maintains an in memory registry of workers
type Worker struct {
ID uint32
Address string
LastSeen time.Time
IsHealthy bool
client grpcapi.WorkerServiceClient // gRPC client TO the worker
conn *grpc.ClientConn
}
type Server struct {
db *db.DB
workers map[uint32]*Worker // Worker registry
mu sync.RWMutex // Thread-safe access
nextWorkerIndex int // For round-robin
stopDispatcher chan struct{}
}goWhen a Coordinator starts, it spawns two background goroutines:
func NewServer(database *db.DB) *Server {
s := &Server{
db: database,
workers: make(map[uint32]*Worker),
stopDispatcher: make(chan struct{}),
}
go s.checkWorkerHealth() // Monitor worker heartbeats
go s.dispatchTasksLoop() // Continuously dispatch tasks
return s
}goThe Dispatch Loop - Every Second the coordinator picks the next task from the database (priority-ordered) finds an available healthy worker and sends the task via gRPC
func (s *Server) dispatchTasks() {
// 1. Atomically pick next task from queue
task, err := s.db.PickNextTask()
if task == nil {
return // No tasks waiting
}
// 2. Find available worker (round-robin)
worker := s.getNextAvailableWorker()
if worker == nil {
// No workers available, put task back
s.db.UpdateTaskStatus(task.ID, db.StatusQueued, nil, nil, nil)
return
}
// 3. Dispatch via gRPC
resp, err := worker.client.SubmitTask(ctx, &grpcapi.TaskRequest{
TaskId: task.ID.String(),
Data: task.Data,
TimeoutSeconds: int32(task.TimeoutSeconds),
})
}goThe Database Schema
The Coordinator doesn’t keep task state in memory, everything lives in PostgreSQL. This is crucial because if the Coordinator restarts, it can recover its state completely from the database.
-- Enable UUID generation
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
-- Task status follows a state machine
CREATE TYPE task_status AS ENUM ('QUEUED', 'STARTED', 'COMPLETED', 'FAILED');
CREATE TABLE tasks (
-- Identity
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
data TEXT NOT NULL, -- The actual command (e.g., "echo hello")
status task_status DEFAULT 'QUEUED',
-- Lifecycle Timestamps (tells the story of each task)
scheduled_at TIMESTAMP DEFAULT NOW(), -- When should this run?
picked_at TIMESTAMP, -- Coordinator claimed it (lease)
started_at TIMESTAMP, -- Worker began execution
completed_at TIMESTAMP, -- Success!
failed_at TIMESTAMP, -- Failure :(
-- Priority Queue (1 = urgent, 10 = whenever)
priority INT DEFAULT 5 CHECK (priority >= 1 AND priority <= 10),
-- Retry Configuration
max_retries INT DEFAULT 3, -- How many times to retry
retry_count INT DEFAULT 0, -- Current attempt number
retry_delay_seconds INT DEFAULT 60, -- Wait between retries
-- Timeout
timeout_seconds INT DEFAULT 300, -- Kill task after 5 minutes
--Results
output TEXT, -- Command stdout/stderr
error_message TEXT, -- Why it failed
created_at TIMESTAMP DEFAULT NOW()
);
-- Critical Index: Fast task picking ordered by priority
CREATE INDEX idx_tasks_priority_scheduled ON tasks (priority ASC, scheduled_at ASC)
WHERE status = 'QUEUED' AND picked_at IS NULL; -- Partial index!go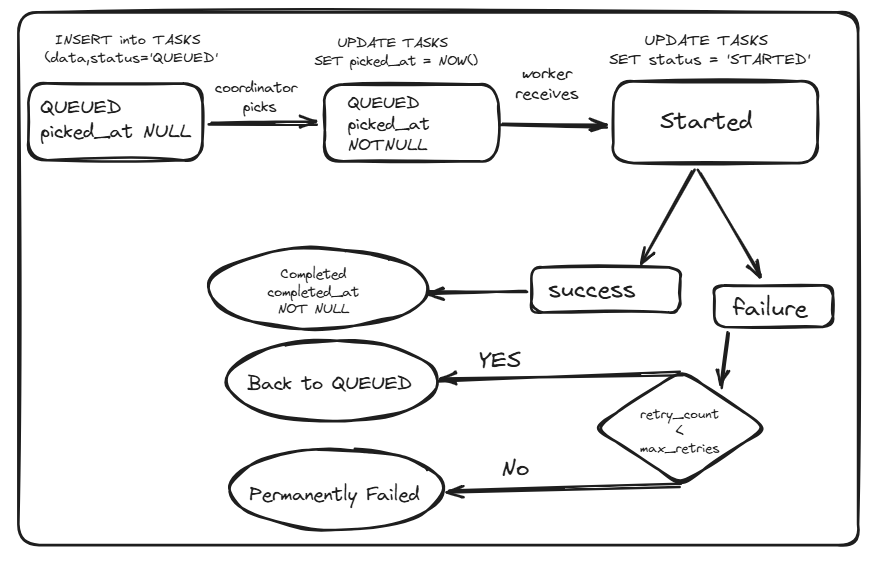
The Workers - The Executors
Workers are the hands of the system - they recieve tasks and actually execute them
Key Responsibilties are such as registering with Coordinator via Heartbeats, Accepts task Assignments via gRPC ,Execute commands with timeout enforcement Report Results back to Coorindator
Each Worker is BOTH
- A gRPC Server to recieve tasks from coordinator
- A gRPC Client to send hearbeats and status updates to Coordinator
type Server struct {
workerID uint32
address string
coordinatorClient grpcapi.CoordinatorServiceClient // To talk TO coordinator
taskQueue chan *grpcapi.TaskRequest // Internal task buffer
}
func NewServer(workerID uint32, address string, coordinatorClient grpcapi.CoordinatorServiceClient) *Server {
s := &Server{
workerID: workerID,
coordinatorClient: coordinatorClient,
taskQueue: make(chan *grpcapi.TaskRequest, 100), // Buffer 100 tasks
}
go s.processTasksLoop() // Consume from task queue
go s.sendHeartbeatLoop() // Keep-alive to coordinator
return s
}goWorker Task Execution
When a worker receives a task, it executes the command in a subprocess with timeout enforcement:
func (s *Server) executeTask(task *grpcapi.TaskRequest) {
// Create context with timeout
ctx, cancel := context.WithTimeout(context.Background(),
time.Duration(task.TimeoutSeconds)*time.Second)
defer cancel()
// Execute the command (e.g., "echo hello" or "python script.py")
cmd := exec.CommandContext(ctx, "sh", "-c", task.Data)
output, err := cmd.CombinedOutput()
// Report result back to coordinator
status := grpcapi.TaskStatus_COMPLETED
errorMsg := ""
if err != nil {
status = grpcapi.TaskStatus_FAILED
if ctx.Err() == context.DeadlineExceeded {
errorMsg = "task timed out"
} else {
errorMsg = err.Error()
}
}
// Send status update via gRPC
s.coordinatorClient.UpdateTaskStatus(context.Background(), &grpcapi.TaskStatusUpdate{
TaskId: task.TaskId,
Status: status,
Output: string(output),
Error: errorMsg,
})
}goThe worker also sends periodic heartbeats to let the coordinator know it’s alive:
func (s *Server) sendHeartbeatLoop() {
ticker := time.NewTicker(5 * time.Second)
for range ticker.C {
s.coordinatorClient.Heartbeat(context.Background(), &grpcapi.HeartbeatRequest{
WorkerId: s.workerID,
Address: s.address,
})
}
}goExecution - The Complete Flow
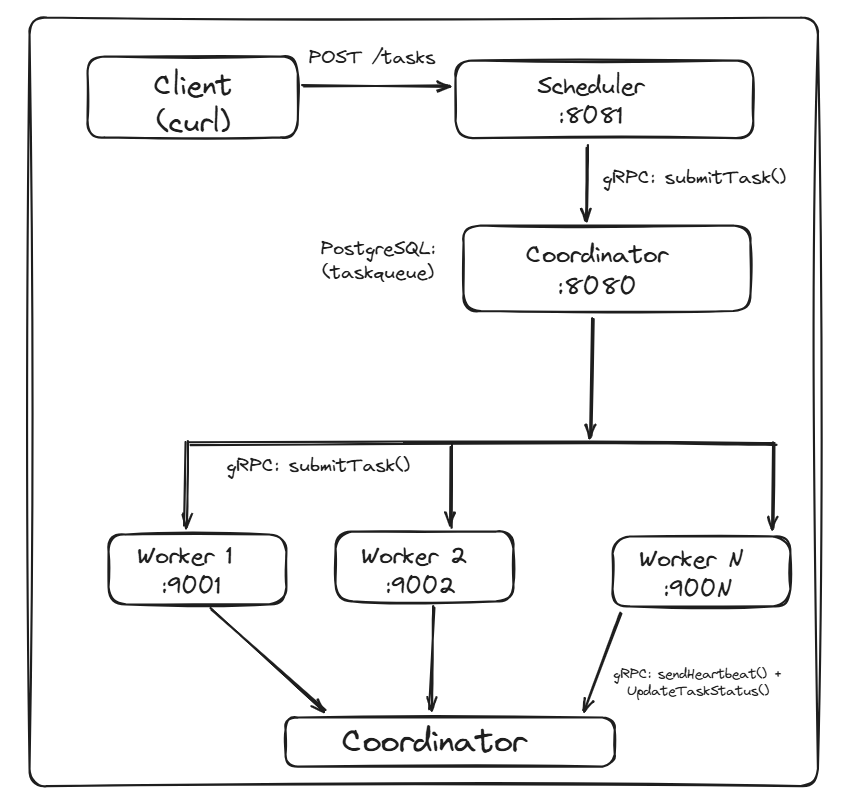
Let’s trace a task from submission to completion:
Step 1: Client Submits Task
curl -X POST http://scheduler:8080/task \
-d '{"data": "echo hello", "priority": 1}'bashThe Scheduler receives this HTTP request and validates it.
Step 2: Scheduler → Coordinator (gRPC)
The Scheduler forwards the task to the Coordinator via SubmitTask RPC. The Coordinator writes it to PostgreSQL with status QUEUED.
Step 3: Coordinator Picks Task
The dispatcher loop runs every second. It executes:
UPDATE tasks SET status = 'STARTED', picked_at = NOW()
WHERE id = (
SELECT id FROM tasks
WHERE status = 'QUEUED'
AND scheduled_at <= NOW()
AND picked_at IS NULL
ORDER BY priority ASC, scheduled_at ASC
LIMIT 1
FOR UPDATE SKIP LOCKED -- Prevents race conditions!
)sqlStep 4: Coordinator → Worker (gRPC)
The Coordinator selects a healthy worker (round-robin) and dispatches the task via SubmitTask RPC.
Step 5: Worker Executes
The Worker runs sh -c "echo hello" with timeout enforcement. If it exceeds timeout_seconds, the process is killed.
Step 6: Worker → Coordinator (Status Update)
Worker reports back: COMPLETED with output “hello\n” or FAILED with error message.
Step 7: Coordinator Updates Database
UPDATE tasks SET
status = 'COMPLETED',
completed_at = NOW(),
output = 'hello\n'
WHERE id = $1;sqlStep 8: Retry Logic (On Failure)
If a task fails and retry_count < max_retries:
if task.RetryCount < task.MaxRetries {
task.RetryCount++
task.Status = "QUEUED"
task.ScheduledAt = time.Now().Add(task.RetryDelay)
// Task re-enters the queue
}Failure Handling
Our system handles several failure modes:
| Failure | Detection | Recovery |
|---|---|---|
| Worker crashes | Heartbeat timeout (30s) | Mark worker unhealthy, task stays in STARTED → cleaned up by Scheduler |
| Coordinator crashes | N/A | Restarts and rebuilds state from PostgreSQL |
| Task times out | Context deadline | Worker kills process, reports FAILED |
| Database down | Connection error | All components retry with backoff |
Conclusion
In this blog, we discussed about the need of a Distributed Task Scheduler,offering a way to overcome the limitations of the regular CronJob. We explored Key Components of Task Scheduler like Scheduler Coordinator and Worker, we went over some of the code snippets to understand the implementation
Key Takeaways:
-
Separation of Concerns - The Control Plane (Scheduler + Coordinator) handles orchestration while the Data Plane (Workers) handles execution. This lets you scale workers independently.
-
Database as Source of Truth - By persisting all state to PostgreSQL, any component can crash and recover without losing tasks.
-
gRPC for Internal Communication - Binary protocol with strong typing beats REST for service-to-service calls.
-
Heartbeats for Health - Simple periodic pings let the Coordinator detect worker failures within seconds.
Trade-offs We Made:
- Single Coordinator - This is a single point of failure. For production, you’d want leader election (using etcd/Consul) or a distributed coordinator.
- PostgreSQL Queue - Works great for thousands of tasks/second. For millions, consider Redis or Kafka as the queue backend.
- Round-Robin Dispatch - Simple but doesn’t account for worker load. A production system might use work-stealing or weighted distribution.
Future Improvements:
- Task dependencies (DAG execution)
- Rate limiting per task type
The full source code is available on GitHub.
Thanks for reading! If you found this helpful, feel free to star the repo or reach out with questions.
